Pull requests and mandatory code reviews have become popular tools for modern software development teams. A tried-and-trusted alternative to pull requests that seems to have fallen out of style is Continuous Integration (CI) and merging to main directly. How did we get there? What are possible benefits of using CI over pull requests? Are these two approaches mutually exclusive? And how could you get started with CI and avoid pull requests moving forward if you wanted to? We’ll explore all of these questions in this blog post. Have fun!
In the past 15 years the way teams collaborate on a shared code base has changed. Thanks to the increasing popularity of distributed version control systems like git and the rise of code forges like GitHub, GitLab and others, collaborating on a shared code base has become more convenient than ever before. A small inventioned called “pull requests”1 lowered the barrier for open source collaboration significantly. They made it easier and more compelling for strangers on the internet to contribute to open source code bases by forking the original repository, making changes like fixing a bug or adding a new feature, and contribute their changes back to the original code repository. Pull requests allow maintainers of code repositories to take their time to review incoming code, leave comments, ask for changes, and ultimately accept or reject a pull request.
What worked incredibly well for open source software projects quickly grew in popularity outside of open source development, too. Teams collaborating on software within companies quickly adopted this pull request-driven workflow and it’s become a seemingly standard practice for software development teams across the globe.
 A pull request or something, don’t ask me how this works.
A pull request or something, don’t ask me how this works.
Honestly, pull requests sound like a pretty sweet tool for collaborating on a shared code base. They are a huge success in the open source space, and looking at that success alone it’s not surprising that a lot of teams use a pull request-based process for themselves. On the other hand, there are a lot of voices out there highlighting how using pull requests as the default mechanism for collaboration can slow down your team and prevent you from getting changes into the hands of your users quickly and reliably. Patterns that worked well for low-trust open source communities, they say, didn’t translate well to teams where you know and trust all of your collaborators. Critics of pull requests often suggest alternative workflows that predate pull requests and even git and other distributed version control systems.
To better understand what they’re talking about, let’s understand how we got here, why exactly pull requests can be problematic, and what good alternatives might look like.
Software Development In a World Before git
Time for an unpleasant truth (it’s unpleasant because it makes me feel old): git, a version control system that eventually grew to become the de-facto standard in today’s world of software development, was released back in 2005. It’s likely that a solid bunch of you folks out there who are now in the software development industry haven’t used any version control system other than git. That’s perfectly fine, you dodged a couple of bullets and missed out on a lot of weird stuff we had to put up with before. To understand how we got to the point we’re at today, let’s first understand how we used to develop software before git (and other distributed version control systems) were a thing.
Before git became popular, software development teams had a few popular options to version control their code. They would either…
- use Subversion (
svn) - be stuck on CVS (
cvs), a predecessor of Subversion - use something proprietary like Visual Source Safe and hate coming into work every damn day
- or — and you’d be shocked to learn how often this happened long until version control systems were a thing — use no version control system at all. Maybe, if you were lucky, there was a shared file system, but that’s about it.
CVS is free, open source, and fairly rudimentary — but it worked well for a lot of teams. Subversion, its successor, also free and open source, took a lot of ideas from CVS and improved on them. Both version control systems (VCS) had a slightly different, dare I say simpler, workflow compared to the distributed version control systems (DVCS) we know today (like git, mercurial, or bazaar if you still remember those). In a regular VCS, your typical workflow would look somewhat like this:
- You check out a local working copy of a code repository
- You make a change to the code on your local machine
- You do a
commit(e.g.svn commit) to send changes from your local working copy directly to the central code repository and share it with everyone
You read that right. A commit would immediately send your code to the central repository, and other developers could pull it with an update operation. There was no such thing as local commits.
Modern DVCS introduced a few super practical bells and whistles on top of that. Here, the same basic workflow would look roughly like this:
- You check out a local working copy of a code repository (e.g. via
git clone <repository>) - You make changes to the code on your local machine
- You add and commit the changes to your local working copy (e.g. via
git add .andgit commit) - You then explicitly push the changes to the upstream code repository (e.g. via
git push origin main) to share it with other developers working on the same code base
DVCS introduced the concept of local commits that you would then push upstream explicitly, whereas traditional VCS immediately shared your changes with the central repository once you did a commit. But that’s only one of many things DVCS gave us — I’ll skip over a lot of that goodness as that’s only tangentially related to the point I’m trying to make. Most importantly, tools like git also gave us a fundamentally better way of branching and merging code. Yes, you could have multiple branches in CVS and Subversion, but branching and merging was a tedious and slow operation with a frustrating developer experience, so it wasn’t exactly popular or part of your regular development workflow for many teams.
As a consequence most CVS and Subversion repositories had one single branch only2, a branch called trunk (remember this name, it’ll come up again later), which is conceptually the same as your main branch in git today.
The massively improved branching and merging capabilities of DVCS like git got a lot of people excited. People started thinking about how to use branches to make their software development workflows better. We got ideas around keeping main (or master as it was called by default back then) only for absolutely stable code, while anything else would live on different branches. This is where the ideas of long-running feature branches and topic branches became popular, and this is where we got much more complicated workflows like git-flow.
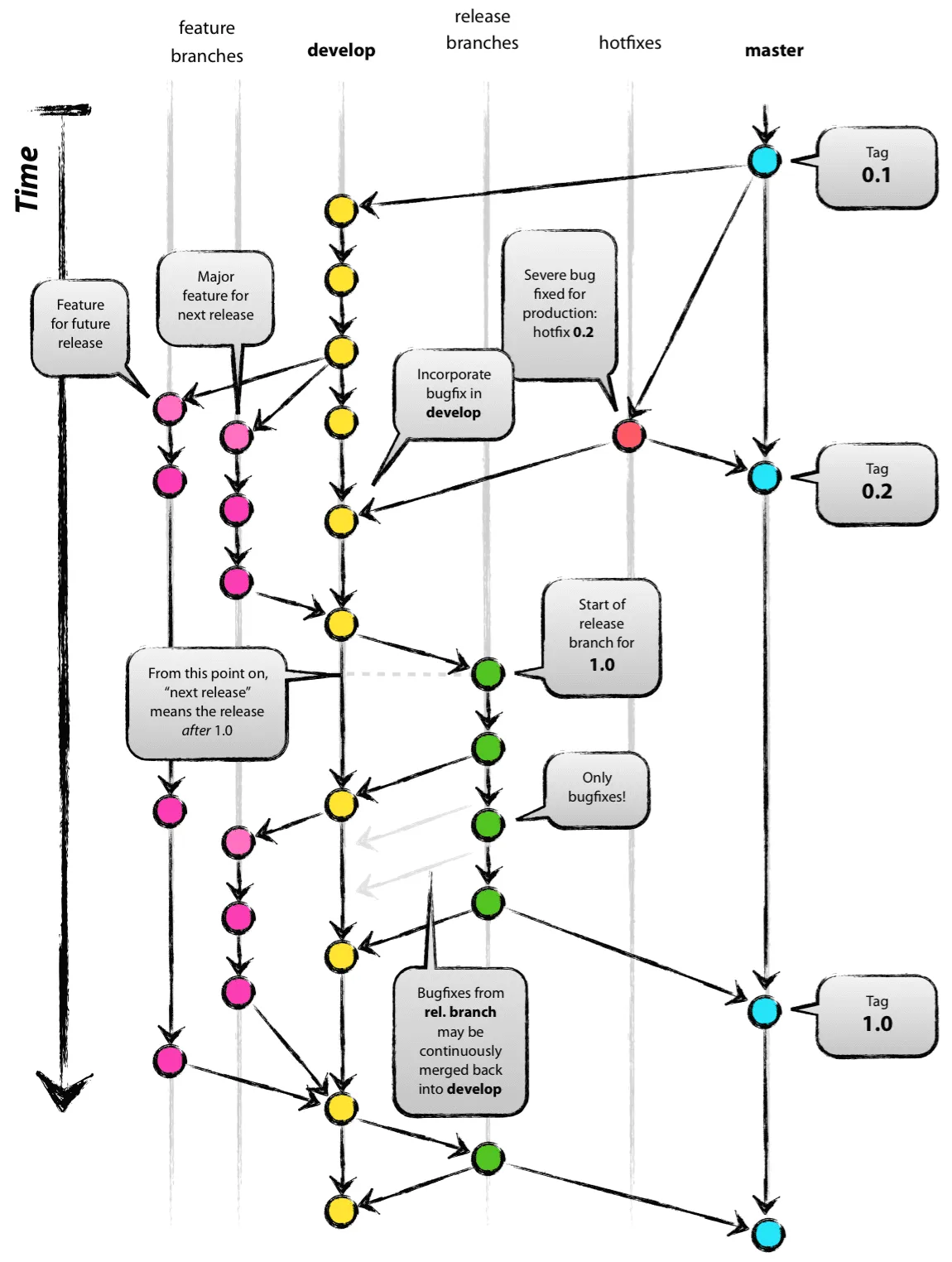 git-flow: fairly complex, and probably too much for a lot of teams out there. (illustration by Vincent Driessen)
git-flow: fairly complex, and probably too much for a lot of teams out there. (illustration by Vincent Driessen)
All of these new workflows were proposed with good intentions. They were supposed to improve the way developers could collaborate on a shared code base. And since branching was easier than ever thanks to these new tools, people were happy to jump on those new workflows, leaving their old ways of collaborating on a single branch (“trunk”) behind.
The Role of Code Forges
On top of the technical capabilities that DVCS like git brought us, code forges like GitHub and GitLab contributed to the rising popularity of branching-oriented workflows as well. They quickly discovered that cheap forking and merging could be used as the foundation for a new way to allow strangers on the open internet to collaborate on open source software and started building a feature called pull requests (or merge requests in GitLab’s case) into their platforms. Pull requests would allow developers to fork a random code base, make changes to their local fork, and propose to send their changes back to the original code base via a pull request. The maintainers of the original code base could then see the incoming changes, review them, ask questions, and ultimately decide whether or not these changes from a total rando on the internet should be included in their code base or not. Pretty sweet. And they built a lovely user interface on top of this to support this entire process as well, what’s not to love?
Feature Branches and Pull Requests
Pull requests work incredibly well for open source projects where people who don’t know each other come together to collaborate on code in a public space. The popularity of this approach quickly seeped into corporate environments. Software development teams in companies small and large started using a very similar workflow for their day-to-day work. In some cases they’d go wild and use the git-flow approach outlined above. In most cases today, however, teams tend to use a simpler process that’s relying on feature branches and pull requests and goes somewhat like this:
- You want to fix a bug or change some code.
- You create a new feature branch for your change
git checkout -b my-feature - You work on your changes and keep committing to your local branch:
git commit -am "my commit message" - Once you’re done with your work, you push your branch to the central repository3 :
git push origin head - You go to GitHub, GitLab or whatever code forge you’re using and set up a pull request that tries to merge your feature branch into the
mainbranch. - After waiting for a while, then waiting some more, then poking someone on Slack, and poking them again, someone else goes to review your pull request. They give you feedback on your changes, and once everything looks good, you merge your pull request into the
mainbranch — sharing it with all other developers working on this repository at this point.
Just Because You Can Doesn’t Mean You Should
The continued popularity of a development workflow revolving around feature branches and pull requests is a matter of debate. Pull requests give you a great opportunity to do code reviews, which in turn can help improve the quality of your code, enforce standards, and detect potential issues before getting a change into your main branch and out to production. The tooling that GitHub, GitLab, Codeberg, and others have built to support this workflow is without any doubt useful, convenient, and a good place to have written-down discussions about code changes that you can reference in the future.
What could possibly be wrong with this?
There are a few voices out there raising concerns about using (long-lived) feature branches when collaborating with a trusted team. While feature branches and a pull request-driven workflow suited open source projects where contributions often come from people you don’t know and trust, this kind of workflow was overkill for teams of trusted team members, they say:
Using pull requests for code changes by your own team members is like having your family members go through an airport security checkpoint to enter your home. It’s a costly solution to a different problem.
Kief Morris, Why your team doesn’t need to use pull requests
Jez Humble, co-author of Continuous Delivery, shared his thoughts about feature branches as early as 2011, when git and the hype around its new branching capabilities were still fairly new:
Here are my observations. When you let large amounts of code accumulate off mainline - code that you ultimately want to release - several bad things happen:
- The longer you leave it, the harder it becomes to merge, because as other people check in to mainline, mainline diverges from your branch. […]
- The more work you do on your branch, the more likely it is you will break the system when you merge into mainline. […]
- When you have more than a handful of developers working on a codebase and people work on feature branches, it becomes difficult to refactor. […]
Jez Humble, On DVCS, continuous integration, and feature branches
Jessica Kerr (jessitron on social media), a proficient conference speaker and software developer criticizes pull request reviews as they often interrupt your team’s flow, lead to context switches, and long waiting times. They improved the flow of an individual while slowing down the team as a whole:
Pull requests are an improvement on working alone. But not on working together. […] Leave the pull requests for collections of individuals sharing a codebase. Give me direct collaboration on my team.
Jessica Kerr, Those pesky pull request reviews
Martin Fowler, one of the most influential thinkers in the field of software development, just revamped his classic article on Continuous Delivery and included a new section about pull requests and reviews that raises a point similar (but a little more nuanced) to Jessica Kerr’s:
The pre-integration code review can be problematic for Continuous Integration because it usually adds significant friction to the integration process. Instead of an automated process that can be done within minutes, we have to find someone to do the code review, schedule their time, and wait for feedback before the review is accepted. Although some organizations may be able to get to flow within minutes, this can easily end up being hours or days - breaking the timing that makes Continuous Integration work.
Martin Fowler, Continuous Integration
“Big deal”, I hear you say, “those are just a bunch of old-timers who refuse to accept that times are changing!”. Yes, there’s a chance these are seasoned developers lamenting about “back in my day” stories and reminiscing approaches to software development that have fallen out of flavor for a good reason.
But is there actually a good reason why these approaches have fallen out of flavor, or did we toss the baby out with the bathwater when we started raving about git’s kick-ass branching and merging capabilities and adopted feature branches as a standard practice for modern software development regardless of context? Maybe, just maybe, these fine folks have a point and we collectively forgot a lesson we learned a good while ago that’s seriously worth reconsidering.
This wouldn’t be the first time.
Continuous Integration - The Thing We Kinda Forgot About
When people complain about feature branches and pull requests, the alternative they suggest is usually the same: Continuous Integration. Some use a different word to mean the same thing, they’ll say Trunk-based Development instead (see? I told you that this “trunk” thing would come back later).
Continuous Integration (CI) is a practice where every developer merges their changes to a shared mainline at least daily. Continuous Integration encourages working in small batches, merging your changes into main at least once per day so that every other developer on your team gets to see your changes. In theory you can pull this off by using feature branches and pull requests, if they’re short-lived enough and get merged within one day. In practice, I’ve yet to see a team that manages to consistently merge all their pull requests within one day. The best way to pull this off consistently is to avoid feature branches and push your changes to main (or “trunk” - hence trunk-based development) directly.
In modern software development the meaning of CI seems to have shifted. We seem to have forgotten about the fundamental aspect of integrating changes into a shared mainline. Instead, CI merely exists as the slightly neglected first half of the casually thrown around “CI/CD” acronym (Continuous Integration/Continuous Delivery) that people use who don’t seem to give too much of a shit about either CI or CD. In today’s conversations “CI” often merely means “run an automated build and a few tests on my feature branch” for a lot of developers, and “CD” means “get that shit deployed somewhere if the tests are green”. While these are absolutely crucial aspects of Continuous Integration and Continuous Delivery, this is far from the whole story.
Again, “big whoop. The semantics shifted, so what? Move with the times and stop lamenting!”, I hear you say.
Not so fast. I think this is important. Considering the integration aspect of CI is what leads to a lot of positive side-effects. Doing proper Continuous Integration nudges you and your team to do a lot of things right:
- It forces you to keep changes small, reducing the chance of introducing risky and breaking changes and increasing your team’s flow
- It avoids constant context switching introduced by mandatory pull request reviews for you and your team, eliminates wait times, and increases your team’s flow
- It requires your team to invest in good, fast, and reliable build and test automation — which in turn will have huge second-order effects
- It makes it easier and more likely that you’ll refactor your code - something that often takes a backseat if you need to go through a tedious pull request review process
A good chunk of these benefits and their second-order effects are well-understood today, thanks to research done by DORA:
Analysis of DevOps Research and Assessment (DORA) data from 2016 (PDF) and 2017 (PDF) shows that teams achieve higher levels of software delivery and operational performance (delivery speed, stability, and availability) if they follow these practices:
- Have three or fewer active branches in the application’s code repository.
- Merge branches to trunk at least once a day.
- Don’t have code freezes and don’t have integration phases.
DORA / Google Cloud - Trunk-Based Development
But What About…
People who are used to feature branches and mandatory pull requests often share concerns when you propose the idea of pushing directly to main or merging branches into main at least once per day.
And I get it. Pull requests give you a sense of control. They give you a check-in point where you can perform a code review. They give you a dedicated time and place to discuss incoming changes and align on what should and should not go into your main branch. They give you room to finish your feature on your own branch without bugging other developers working on the same repository. But at what cost? And how would you do all of these things if it wasn’t for feature branches and pull requests?
Often these things can be done more effectively before you get to the point where a teammate created a pull request:
Code reviews are a great idea — consider doing them early and often, maybe in the form of pair or ensemble programming. Aligning on and discussing design decisions is important to come up with high-quality software that serves the needs of your users and is maintainable in the long run. If you’re having the first discussion about the design of a feature when someone finished their work and put together a pull request, that’s way too late. At this point you’re up for a frustrating debate if you’re asking for substantial changes, as your teammate has already gone through all the effort of implementing the current solution and doesn’t want to redo it all. Consider using automated linters and static code analysis to spot code inconsistencies instead of nitpicking about stylistic aspects in code reviews. Instead of building your entire feature on a feature branch, and only merging it after you’re completely done, consider breaking down your work, use feature flags, branch-by-abstraction, and hide work in progress from your users.
Avoiding pull requests and feature branches can feel uncomfortable. Ask yourself: Is this feeling of discomfort something you should lean into? Are you uncomfortable about the idea of using Continuous Integration because somewhere deep down you know that your build takes ages and everyone’s sick of it? Or are your automated tests constantly falling for no good reason? Maybe you secretly distrust your team members or enjoy being the gate keeper who gets to say what goes into main? If any of these are true, you’ve got more fundamental problems to solve. Listen to this feeling of discomfort and address the actual problem instead of applying mandatory pull requests as a band-aid solution that makes you feel better but leaves the fundamental problems unaddressed.
If You Want To Learn More
Changing from feature branching to Continuous Integration can be a big and scary change4. It requires a different mindset and a practices from you and your team. And, most importantly, it requires bold experimentation and a lot of trust. Consider moving away from pull requests and (long-lived) feature branches gradually, for example by using the Ship/Show/Ask approach, to get a better feeling for Continuous Integration without having to go all-in over night. You might also start applying Continuous Integration in one single repository only, with one single team, to learn more about it while leaving everything else untouched.
I’ve worked in a lot of teams that used Continuous Integration instead of long-lived feature branches, and I can say without any doubt that the work on these teams was more productive, more fun, and led to a healthier code base and better team habits than I experienced in teams who use feature branches and mandatory code reviews. This is, of course, just my personal anecdote (which seems to align with the research) — I can only encourage you to give it a try and see if you experience similar results.
If you want to learn more, let me point you to a few useful resources:
In his freshly updated article Martin Fowler shares a lot of insights on the practices and benefits of using Continuous Integration and answers a lot of common questions for folks who have never worked this way.
The DORA folks share similar insights in their articles about Trunk-Based Development and Continuous Integration.
I also recommend checking out Paul Hammant’s insights on the benefits, nuances, and practices of Trunk-Based Development.
If you don’t mind diving into the classics (risking that some of this feels a little dated from today’s perspective), Kent Beck’s Extreme Programming Explained: Embrace Change is the book that sparked the original idea of Continuous Integration and explained a lot of practices that work well with CI.
And finally, Thierry de Pauw wrote an elaborate series on the evilness of feature branching in which he analyzes why teams tend to use feature branches, how this might be problematic, and counters quite a few common discussion points like compliance and code reviews.
Continuous Integration is far from a new idea. But it’s one whose meaning seems to have shifted and become more blurry in recent years. Our industry has a tendency to forget about lessons we’ve learned a good while ago and to write off older ideas as outdated and unsuitable for modern development. Our industry evolves, constantly and quickly, but that doesn’t meant that lessons learned before aren’t worth keeping or reconsidering. If any of the above sounds convincing to you, I whole-heartedly encourage you to give proper Continuous Integration a chance. Try to move away from feature branches and pull requests, and do it like you mean it. You might discover that you like this new (old) way of working.
Have fun!
Footnotes
-
GitLab calls them “merge requests”, but I’ll use the term “pull request” to mean both from here on out. ↩
-
Yes, I am aware that release branches were a thing for a lot of teams back then. But that’s not what I’m getting at. ↩
-
The fact that most of us use one single central repository hosted on services like GitHub and GitLab isn’t necessary for a distributed version control system, but it’s become the de-facto standard for most teams. ↩
-
Ask me how hard it is to pull off this change at Stack Overflow over a beer someday. ↩